SpringAI基于向量数据库PGVector和智谱大模型实现RAG
SpringAI基于向量数据库PGVector和智谱大模型实现RAG

本专栏上一篇文章分享了LangChain4j实战-Java AI应用开源框架之LangChain4j和Spring AI今天这篇文章我来分享SpringAI基于向量数据库PGVector和智谱大模型实现RAG和知识文档向量化本地存储。
文章最后可以加入免费的Java&AI技术和支付系统沟通社群,一起探讨Java/你的产品如何与AI结合,请按照要求加入。在群中可以聊开发、系统设计、架构、行业趋势、AI等等话题
完整代码在文章最后,如果觉得本篇文章对你有用,记得点赞、关注、收藏哦。你的支持是我持续更新的动力!
AI专栏软件环境
- IntelliJ IDEA2024.3.3
- Spring AI 1.0.0-SNAPSHOT
- Spring Boot 3.4.3
- Spring 6.2.3
- pgvector 0.8.0
- postgresql 16.6
- 智谱大模型
- JDK 17.0.12
我们先看本篇文章对应的项目结构,请看下图
相关软件下载地址
postgresql:https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
Pgvector:https://github.com/pgvector/pgvector
PgVector向量数据库的安装:
你可以使用官方提供的本地安装方式 https://github.com/pgvector/pgvector
1 什么是RAG
RAG是Retrieval-Augmented Generation的缩写,中文可以翻译为检索增强生成。它是一种结合了信息检索和语言生成模型的技术方法。具体来说:
- 信息检索:从大量的文档或数据集中检索出与用户查询最相关的部分。
- 语言生成:利用语言模型根据检索到的相关信息生成回答。
这种方式使得生成的回答不仅依赖于预训练的语言模型知识,还能结合最新的、特定领域的文档信息,从而提高回答的准确性和时效性
2 向量数据库能做什么
针对传统大模型的Token限制,开发人员想到了一种解决方案,就是使用向量数据库。向量数据库除了存储必要的元数据(如文本、图片、音频)外,还会存储对应元数据的向量。与传统的数据库执行的精确性搜索不同的是,向量数据库执行的是相似性检索。执行相似性检索的算法有很多,比较容易理解的是计算两个向量之间的距离来判断是否相似。目前主流的向量数据库有:
- Chroma https://www.trychroma.com/
- Milvus https://milvus.io/
- Pgvector https://github.com/pgvector/pgvector/
- Redis https://redis.io/
- Neo4j https://neo4j.com/
向量数据库是一种专门用于存储和检索向量数据的数据库,它在人工智能、机器学习等领域有着广泛的应用,主要体现在以下几个方面:
- 自然语言处理:在自然语言处理任务中,向量数据库可用于存储文本的向量表示。通过将文本转换为向量,向量数据库可以快速找到与查询文本语义相似的文本,从而实现文本的检索和匹配。例如,在智能客服系统中,向量数据库可以快速找到与用户问题最相关的答案,提高客服效率和质量。
- 图像和视频检索:向量数据库可以存储图像和视频的特征向量,通过计算向量之间的相似度,实现图像和视频的快速检索。例如,在安防监控系统中,向量数据库可以快速找到与特定目标图像相似的监控视频片段,帮助安保人员快速定位目标。在电商平台中,用户可以通过上传图片来搜索相似的商品,这背后就离不开向量数据库的支持。
- 欺诈检测:在金融领域,向量数据库可以用于存储和分析交易数据的向量表示。通过计算向量之间的相似度,向量数据库可以快速发现与正常交易模式不同的异常交易,从而帮助金融机构及时发现和防范欺诈行为。
- 物联网(IoT):在物联网场景中,向量数据库可以用于存储和分析传感器数据的向量表示。通过对传感器数据进行实时分析,向量数据库可以快速发现数据中的异常模式,从而为设备故障预警、能源管理等提供支持。
向量数据库通过高效地存储和检索向量数据,为各种需要处理和分析大规模数据的应用提供了强大的支持,极大地提升了数据处理的效率和准确性。
3 项目搭建
3.1 pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>cn.itbeien.ai</groupId>
<artifactId>spring-ai-labs</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>spring-ai-lab04</artifactId>
<properties>
<postgresql-version>42.7.5</postgresql-version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-zhipuai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>${postgresql-version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
</dependencies>
</project>3.2 配置信息
spring.datasource.username=postgres
spring.datasource.password=123456
spring.datasource.url=jdbc:postgresql://localhost/vector_store
# 智谱开放平台 https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys
spring.ai.zhipuai.api-key=你自己的key
spring.ai.zhipuai.base-url=https://open.bigmodel.cn/api/paas/
spring.ai.vectorstore.pgvector.index-type=hnsw
#spring.ai.vectorstore.pgvector.initialize-schema=true3.3 文件服务类
package cn.itbeien.ai.springai.service;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.List;
/**
* @author itbeien
* 项目网站:https://www.itbeien.cn
* 公众号:贝恩聊架构
* 全网同名,欢迎小伙伴们关注
* Java/AI学习社群
* Copyright© 2025 itbeien
*/
@Service
public class FileService {
@jakarta.annotation.Resource
private VectorStore vectorStore;
private TokenTextSplitter tokenTextSplitter;
@Bean
public TokenTextSplitter tokenTextSplitter() {
tokenTextSplitter = new TokenTextSplitter();
return tokenTextSplitter;
}
public void saveResourceFile(MultipartFile file) throws IOException {
// 获取上传文件的原始文件名
String fileName= file.getOriginalFilename();
// 创建临时文件
Path tempFile = Files.createTempFile("rag-temp-", fileName);
// 将上传文件写入临时文件
Files.write(tempFile, file.getBytes());
// 将临时文件转换为Resource对象
Resource fileResource = new FileSystemResource(tempFile.toFile());
// 创建MarkdownDocumentReaderConfig对象
MarkdownDocumentReaderConfig loadConfig = MarkdownDocumentReaderConfig.builder().build();
// 创建MarkdownDocumentReader对象
MarkdownDocumentReader markdownDocumentReader=new MarkdownDocumentReader(fileResource, loadConfig);
// 将MarkdownDocumentReader对象中的内容分割成token,并传入vectorStore
vectorStore.accept(tokenTextSplitter.apply(markdownDocumentReader.get()));
}
}3.4 RAG服务类
package cn.itbeien.ai.springai.service;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.zhipuai.ZhiPuAiChatModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.ai.chat.messages.Message;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* @author itbeien
* 项目网站:https://www.itbeien.cn
* 公众号:贝恩聊架构
* 全网同名,欢迎小伙伴们关注
* Java/AI学习社群
* Copyright© 2025 itbeien
*/
@Service
public class RagService {
private final static String SYSTEM_PROMPT = """
你需要使用我提供的文档内容对用户提出的问题进行回答,
当用户提出的问题无法根据文档内容进行回复或者你也不知道时,回答不知道即可。
文档内容如下:
{documents}
""";
@Autowired
private ZhiPuAiChatModel chatModel;
@Autowired
private VectorStore vectorStore;
public String ragByVectorStore(String message) {
// 根据输入的消息,在向量库中进行相似度搜索,获取相似文档列表
List<Document> listOfSimilarDocuments = vectorStore.similaritySearch(message);
// 断言相似文档列表不为空
assert listOfSimilarDocuments != null;
// 将相似文档列表中的文本内容拼接成一个字符串
String documents = listOfSimilarDocuments.stream().map(Document::getText).collect(Collectors.joining());
// 创建系统消息,将拼接的文本内容作为参数传入
Message systemMessage = new SystemPromptTemplate(SYSTEM_PROMPT).createMessage(Map.of("documents", documents));
// 创建用户消息,将输入的消息作为参数传入
UserMessage userMessage = new UserMessage(message);
// 调用聊天模型,将系统消息和用户消息作为参数传入
ChatResponse rsp = chatModel.call(new Prompt(List.of(systemMessage, userMessage)));
// 返回聊天模型的输出结果
return rsp.getResult().getOutput().getText();
}
}4 单元测试
4.1 准备行业文档
先准备一个你的专属知识文档,RAG文档内容如下,md格式

4.2 测试系统
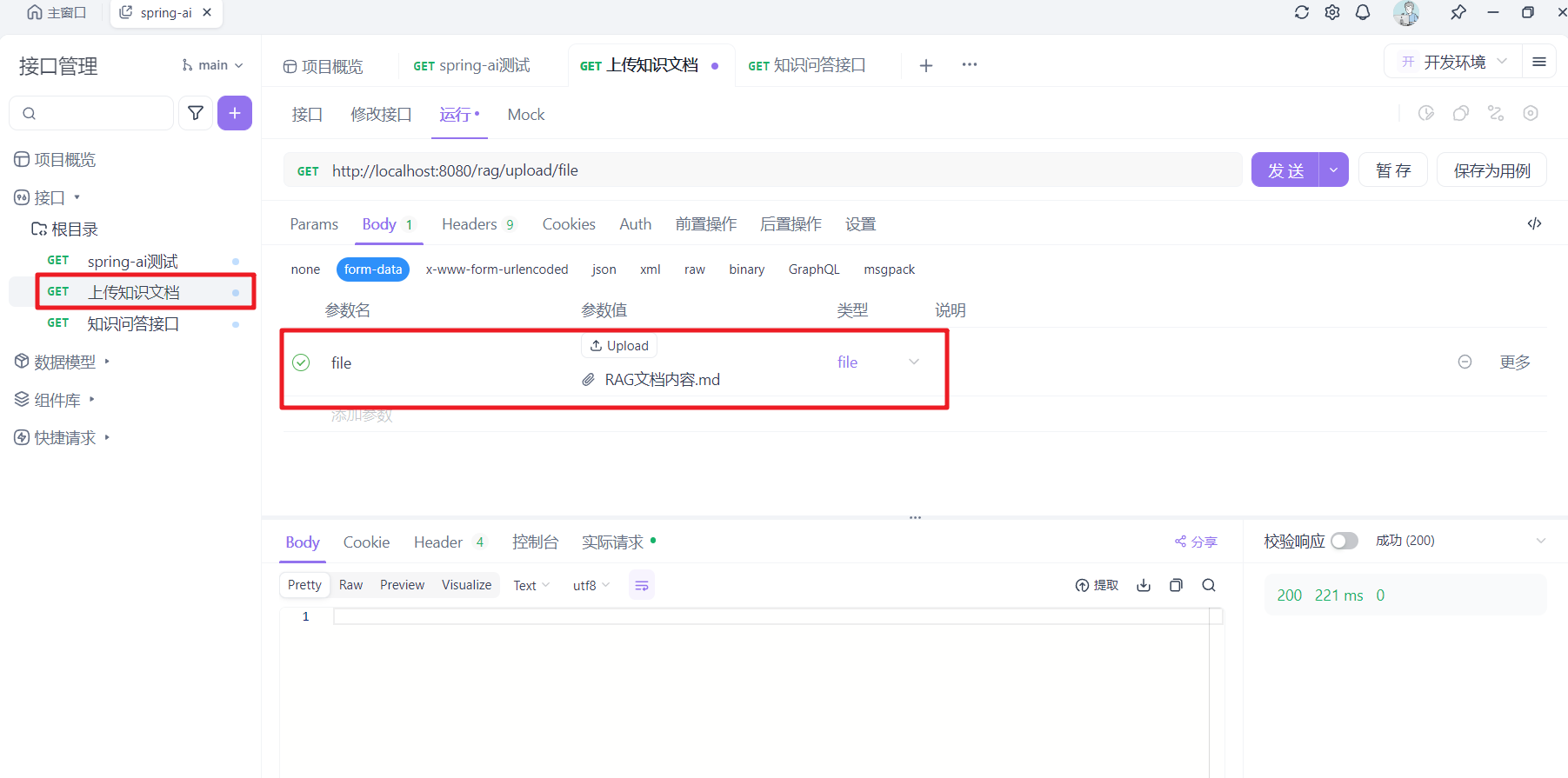
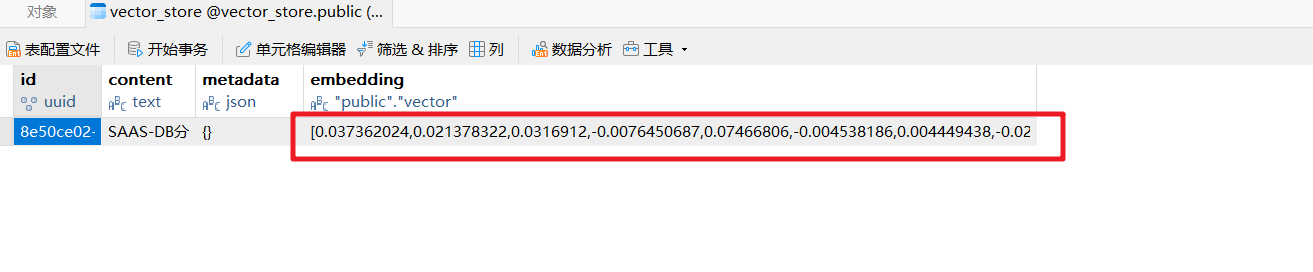
先上传知识文档,把文档进行向量化存储
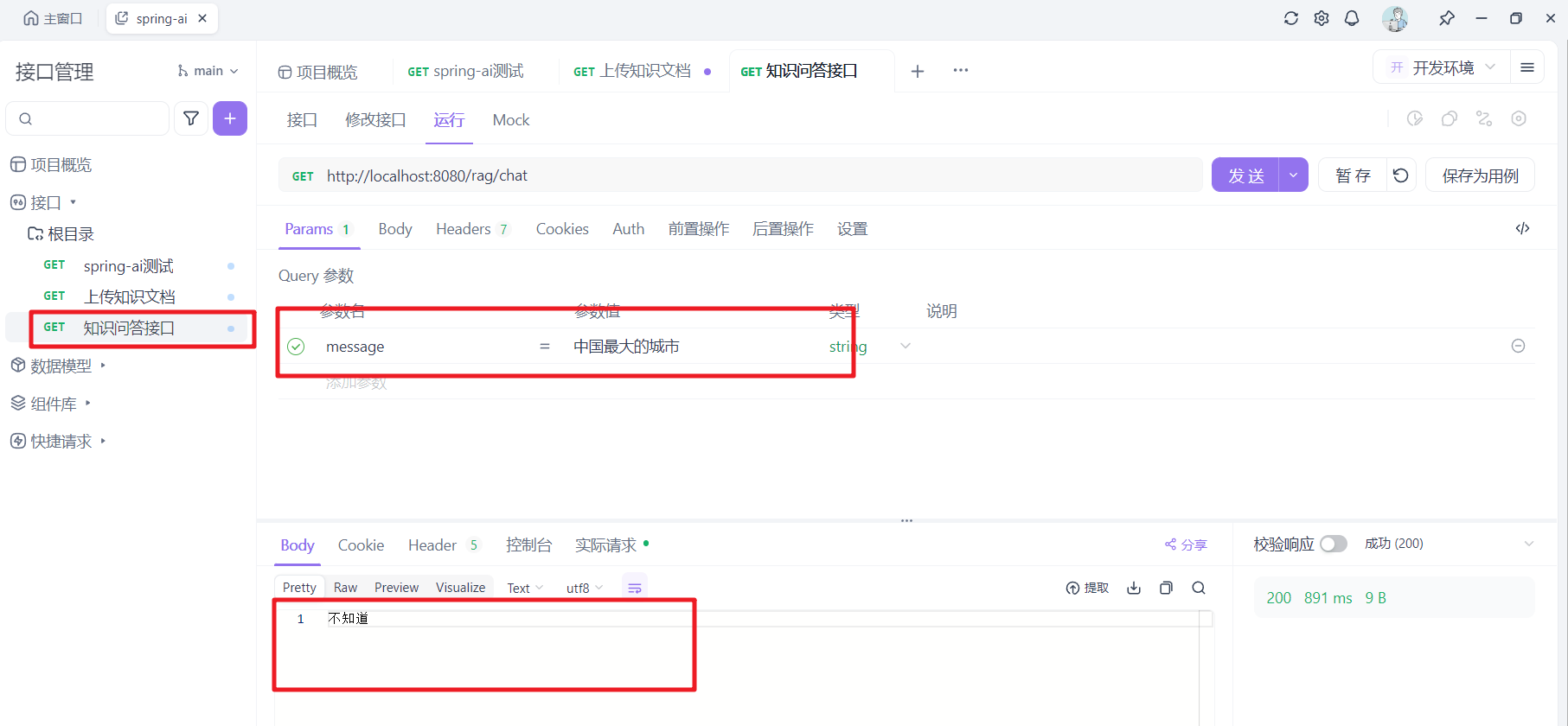
4.3 知识问答
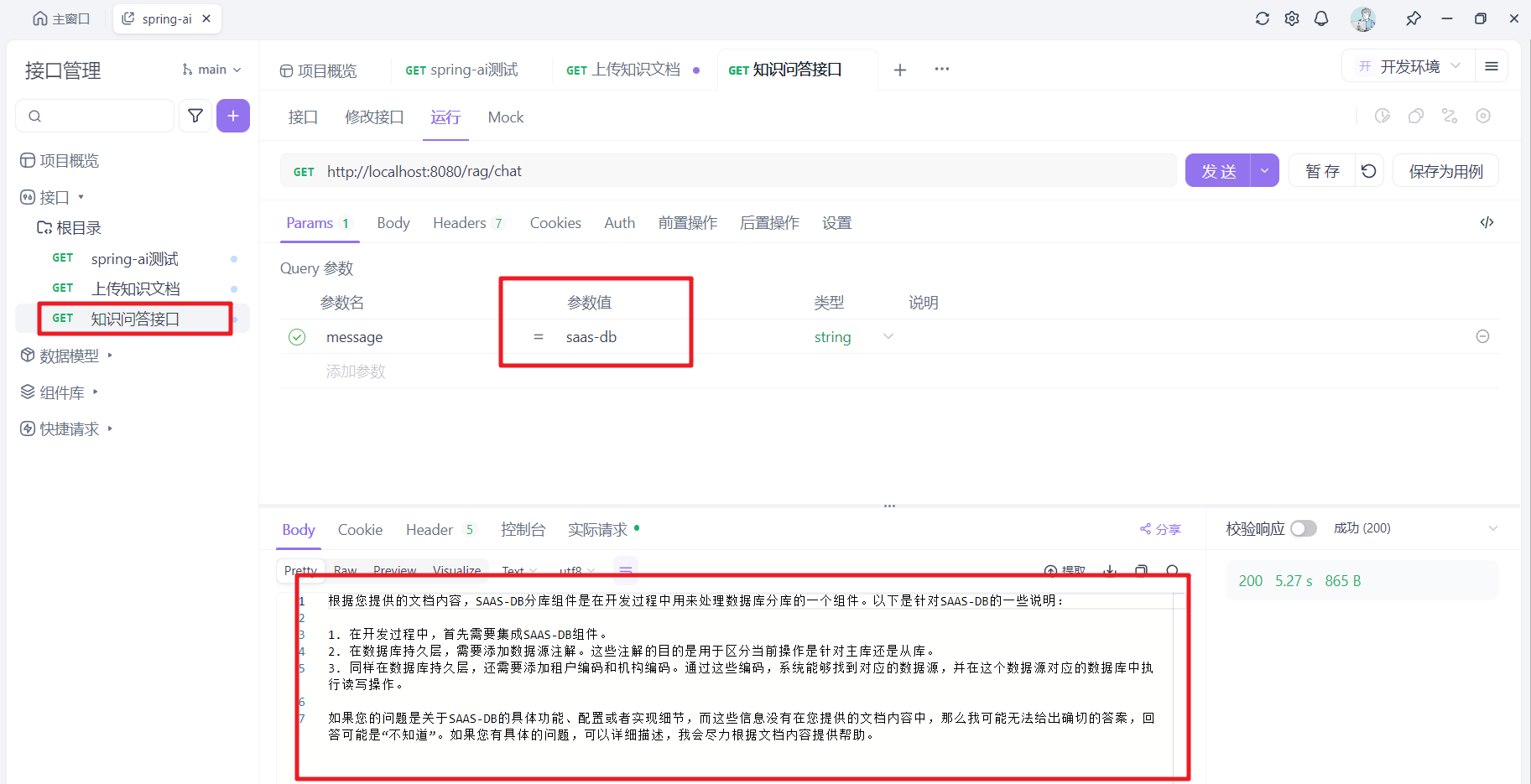
先提问知识库中的问题,看系统如何回答
再提一个知识库中没有的问题,看系统如何回答
以上就是今天SpringAI基于向量数据库PGVector和智谱大模型实现RAG和知识文档向量化本地存储全部内容,文章最后有源码下载地址
欢迎大家关注我的项目实战内容itbeien.cn,一起学习一起进步,在项目和业务中理解各种技术。
欢迎沟通交流Java/AI技术和支付业务,一起探讨大模型应用/SAAS多租户/聚合支付/预付卡系统业务、技术、系统架构、微服务、容器化。并结合大模型应用/SAAS多租户/聚合支付系统深入技术框架/微服务原理及分布式事务原理。加入我的知识星球吧
AI专栏
01IDEA&VsCode集成DeepSeek-V3 API提高编程效率
02IntelliJ IDEA集成主流 AI 编程助手及特性介绍
03Spring AI快速入门-基于DeepSeek&智谱实现聊天应用
04Spring AI中流式对话API如何使用-基于DeepSeek
06SpringAI实现角色扮演(自定义人设)和Prompts模板语法-基于DeepSeek
07LangChain4j实战-Java AI应用开源框架之LangChain4j和Spring AI
SpringBoot3专栏
01SpringBoot3专栏-SpringBoot3.4.0整合Mybatis-plus和Mybatis
02SpringBoot3.4.0结合Mybatis-plus实现动态数据源
03mapstruct对象映射在Springboot3中这样用就对了
04RocketMQ5.3.1集成SpringBoot3.4.0就这样简单
05SpringBoot3.4.0整合Redisson实现分布式锁
06MySQL增量数据同步利器Canal1.1.7环境搭建流程
07SpringBoot3.4.0集成Canal1.1.7实现MySQL实时同步数据到Redis
08基于Docker-SpringBoot3.4.0集成Apache Pulsar4.0.1实现消息发布和订阅
09SpringBoot3.4.0整合消息中间件Kafka和RabbitMQ
10SpringBoot3.4.0整合ActiveMQ6.1.4
11SpringBoot3整合Spring Security6.4.2 安全认证框架实现简单身份认证
12SpringBoot3.4.1和Spring Security6.4.2实现基于内存和MySQL的用户认证
13SpringBoot3.4.1和Spring Security6.4.2结合OAuth2实现GitHub授权登录
14SpringBoot3.4.1和Spring Security6.4.2结合JWT实现用户登录
16SpringBoot3.4.1基于MySQL8和Quartz实现定时任务管理
17SpringBoot3.4.2基于MyBatis和MySQL8多数据源使用示例
18SpringBoot3.4.3实现(文本/附件/HTML/图片)类型邮件发送案例
19SpringBoot3.4.3实现文件上传和全局异常处理
20SpringBoot3.4.3集成Knife4j实现接口文档管理和调试
21SpringBoot3.4.3基于Caffeine实现本地缓存
22SpringBoot3.4.3基于Spring WebFlux实现SSE功能
23SpringBoot3.4.3基于SpringDoc2和Swagger3实现项目接口文档管理
跟着我学微服务系列
01跟着我学微服务,什么是微服务?微服务有哪些主流解决方案?
05SpringCloudAlibaba之图文搞懂微服务核心组件在企业级支付系统中的应用
06JDK17+SpringBoot3.4.0+Netty4.1.115搭建企业级支付系统POS网关
07JDK17+SpringCloud2023.0.3搭建企业级支付系统-预付卡支付交易微服务
08JDK17+Dubbo3.3.2搭建企业级支付系统-预付卡支付交易微服务
09JDK17+SpringBoot3.3.6+Netty4.1.115实现企业级支付系统POS网关签到功能
贝恩聊架构-项目实战地址
欢迎大家一起讨论学习,加我备注"Java/AI"拉你进入Java&AI技术讨论群,备注"聚合支付"拉你进入支付系统讨论群,在技术学习、成长、工作的路上不迷路!加我后不要急,每天下午6点左右通过!营销号免入

5 源码地址
贝恩聊架构-SpringBoot3专栏系列文章、资料和源代码会同步到以下地址,代码和资料每周都会同步更新
该仓库地址主要用于存放贝恩聊架构-SpringBoot3专栏、贝恩聊架构-AI专栏、基于企业级支付系统学习微服务整体技术栈所有资料和源码
